
An attribute analysis primer
/
A question on Stack Exchange the other day reminded me of the black magic feeling I used to have about attribute analysis. It was all very meta: statistics of combinations of attributes, with shifted windows and crazy colourbars. I realized I haven't written much about the subject, despite the fact that many of us spend a lot of time trying to make sense of attributes.
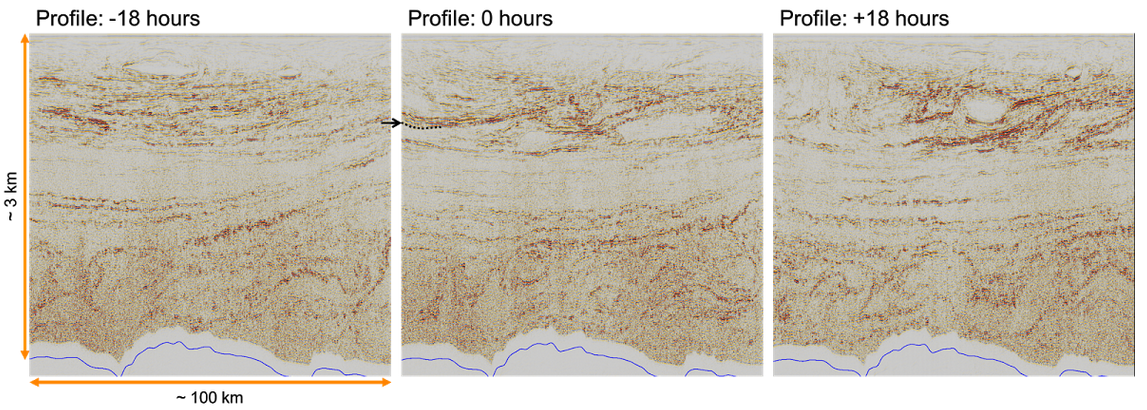
Time slices, horizon slices, and windows
One of the first questions a new attribute-analyser has is, "Where should the window be?" Like most things in geoscience: it depends. There are lots of ways of doing it, so think about what you're after...
- Timeslice. Often the most basic top-down view is a timeslice, because they are so easy to make. This is often where attribute analysis begins, but since timeslices cut across stratigraphy, not usually where it ends.
- Horizon. If you're interested in the properties of a strong reflector, such as a hard, karsted unconformity, maybe you just want the instantaneous attribute from the horizon itself.
- Zone. If the horizon was hard to interpret, or is known to be a gradual facies transition, you may want to gather statistics from a zone around it. Or perhaps you couldn't interpret the thing you really wanted, but only that nice strong reflection right above it... maybe you can bootstrap yourself from there.
- Interval. If you're interested in a stratigraphic interval, you can bookend it with existing horizons, perhaps with a constant shift on one or both of them.
- Proportional. If seismic geomorphology is your game, then you might get the most reasonable inter-horizon slices from proportionally slicing in between stratigraphic surface. Most volume interpretation software supports this.
There are some caveats to simply choosing the stratigraphic interval you are after. Beware of choosing an interval that strong reflectors come into and out of. They may have an unduly large effect on most statistics, and could look 'geological'. And if you're after spectral attributes, do remember that the Fourier transform needs time! The only way to get good frequency resolution is to provide long windows: a 100 ms window gives you frequency information every 10 Hz.
Extraction depends on sample interpolation
When you extract an attribute, say amplitude, from a trace, it's easy to forget that the software has to do some approximation to give you an answer. This is because seismic traces are not continuous curves, but discrete series, with samples typically every 1, 2, or 4 milliseconds. Asking for the amplitude at some arbitrary time, like the point at which a horizon crosses a trace, means the software has to interpolate between samples somehow. Different software do this in different ways (linear, spline, polynomial, etc), and the methods give quite different results in some parts of the trace. Here are some samples interpolated with a spline (black curve) and linearly (blue). The nearest sample gives the 'no interpolation' result.
As well as deciding how to handle non-sampled parts of the trace, we have to decide how to represent attributes operating over many samples. In a future post, we'll give some guidance for using statistics to extract information about the entire window. What options are available and how do we choose? Do we take the average? The maximum? Something else?
There's a lot more to come!
As I wrote this post, I realized that this is a massive subject. Here are some aspects I have not covered today:
- Calibration is a gaping void in many published workflows. How can we move past "that red blob looks like a point bar so I drew a line around it in PowerPoint" to "there's a 70% chance of finding reservoir quality sand at that location"?
- This article was about single-trace attributes at single instants or over static windows. Multi-trace and volume attributes, like semblance, curvature, and spectral decomposition, need a post of their own.
- There are a million attributes (though only a few that count, just ask Art Barnes) so choosing which ones to use can be a challenge. Criteria range from what software licenses you have to what is physically reasonable.
- Because there are a million attributes, the art of combining attributes with statistical methods like principal component analysis or multi-linear regression needs a look. This gets into seismic inversion.
We'll return to these ideas over the next few weeks. If you have specific questions or workflows to share, please leave a comment below, or get in touch by email or Twitter.
To view and run the code that I used in creating the figures for this post, grab the iPython/Jupyter Notebook.




































 Except where noted, this content is licensed
Except where noted, this content is licensed