
x lines of Python: Loading images
/Difficulty rating: Beginner
We'd often like to load images into Python. Once loaded, we might want to treat them as images, for example cropping them, saving in another format, or adjusting brightness and contrast. Or we might want to treat a greyscale image as a two-dimensional NumPy array, perhaps so that we can apply a custom filter, or because the image is actually seismic data.
This image-or-array duality is entirely semantic — there is really no difference between images and arrays. An image is a regular array of numbers, or, in the case of multi-channel rasters like full-colour images, a regular array of several numbers: one for each channel. So each pixel location in an RGB image contains 3 numbers:
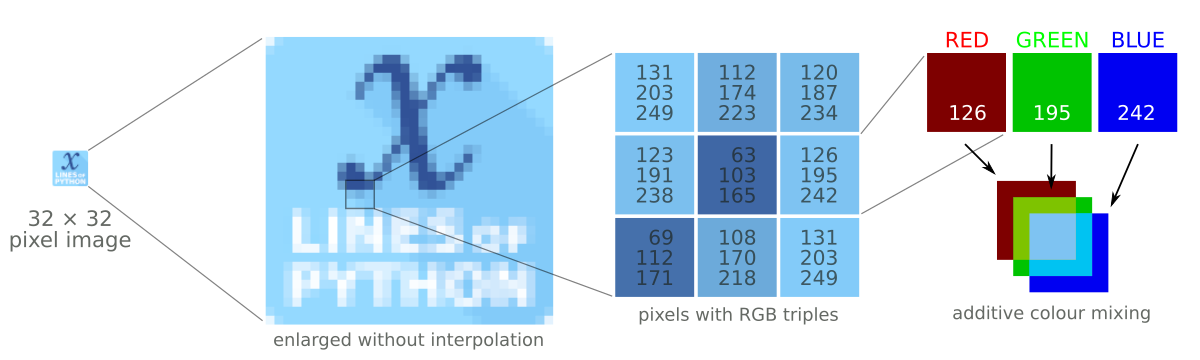
In general, you can go one of two ways with images:
- Load the image using a library that 'knows about' (i.e. uses language related to) images. The preeminent tool here is
pillow(which is a fork of the grandparent of all Python imaging solutions,PIL). - Load the image using a library that knows about arrays, like
matplotliborscipy. These wrapPIL, making it a bit easier to use, but potentially losing some options on the way.
The Jupyter Notebook accompanying this post shows you how to do both of these things. I recommend learning to use some of PIL's power, but knowing about the easier options too.
Here's the way I generally load an image:
from PIL import Image im = Image.open("my_image.png")
(One strange thing about pillow is that, while you install it with pip install pillow, you still actually import and use PIL in your code.) This im is an instance of PIL's Image class, which is a data structure especially for images. It has some handy methods, like im.crop(), im.rotate(), im.resize(), im.filter(), im.quantize(), and lots more. Doing some of these operations with NumPy arrays is fiddly — hence PIL's popularity.
But if you just want your image as a NumPy array:
import numpy as np arr = np.array(im)
Note that arr is a 3-dimensional array, the dimensions being row, column, channel. You can go off with arr and do whatever you need, then cast back to an Image with Image.fromarray(arr).
All this stuff is demonstrated in the Notebook accompanying this post, or you can use one of these links to run it right now in your browser:
![]() Run the accompanying notebook in MyBinder
Run the accompanying notebook in MyBinder
Other posts about images:
- How to choose an image format (2012)
- When to use vectors not rasters (2012)
- Images as data (2016)
- Save the samples (2014)
- B is for bit depth (2011)









 Except where noted, this content is licensed
Except where noted, this content is licensed