
Why do wavelets have sidelobes?
/Brian Romans (a geology professor at Virginia Tech) asked a great question in the Software Underground’s Slack earlier this month:
“I was teaching my Seismic Stratigrapher course the other day and a student asked me about the origin of ‘side lobes’ on the Ricker wavelet. I didn’t have a great answer [...] what is a succinct explanation for the side lobes?”
Questions like this are fantastic because they really aren’t easy to answer. There’s usually a breadcrumb trail of concepts that lead to an answer, but the trail might be difficult to navigate, and some of those breadcrumbs will lead to more questions… and soon you’ve written a textbook on signal processing.
Here’s how I attempted, rather long-windedly, to help Brian’s student (edited a bit for brevity):
Wavelets measure displacement, or velocity, or acceleration (or some proxy for these things like voltage or capacitance), but eventually we can compute a signal that represents displacement. (In seismic reflection surveys, we don't care about the units.)
The Ricker wavelet represents an impulsive signal (the 'bang' of dynamite or the 'pop' of an airgun; let's leave Vibroseis out of it for now). The impulse is bandlimited ('band' as in radio band) — in other words, it doesn't contain all frequencies. Unfortunately, you need a lot of frequencies to represent very sudden or abrupt (short in time) things like bangs and pops, otherwise they spread out in time. Since our wavelet is restricted to a band of frequencies (eg 10 to 80 Hz), it must be (infinitely) spread out in time.
Additionally, since the frequencies don't contain what we call a 'DC' signal (0 Hz, in other words a bias or shift), it must return to zero when displaced. So it starts and ends on zero amplitude.
So the wavelet is spread out, and it starts and ends on zero amplitude. Why does it wiggle? In other words, why is seismic oscillatory? It's not the geophone: although it contains a spring (or something like one), its specially chosen/tuned to be able to move freely at the frequencies we're trying to record. So it's the stiffness of the earth itself which causes the oscillation, dissipating the vibrational energy (as heat) and damping the signal. At least, this explains why it dies out, but not really why it oscillates... Physics! Simple harmonic motion! Or something.
Yeah, I guess I’m a bit hazy on the micro-mechanics of wave propagation. Evan came to my rescue (see below), but I had a couple more things to say first:
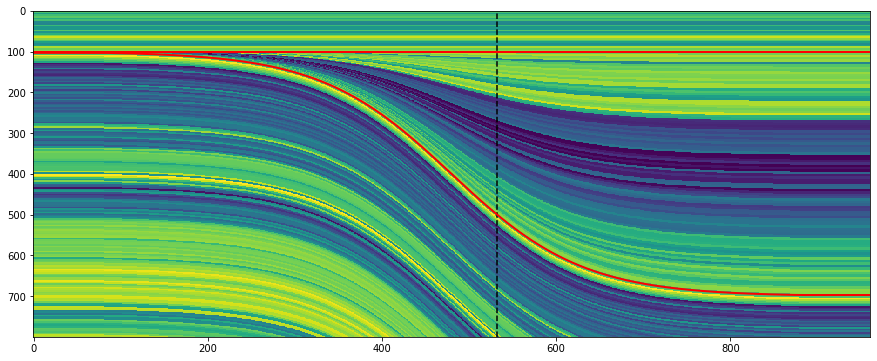
The other thing is that classic wavelets like the Ricker are noncausal, aka non-realizable, because they have energy at negative time (i.e. they are centered around t = 0) and there’s no such thing as negative time. This is a clue that a zero-phase wavelet is a geological convenience contrived during processing, not a physical thing. The field seismic data would contain a so-called 'minimum phase' wavelet, which looks more like what you'd expect a recording of a dynamite blast to look like (see below).

To try to make up for the fact that I trailed off at ‘simple harmonic motion’, Evan offered this:
If you imagine the medium being made up of a bunch of particles, then propagating a wave means causing a stress (say, sudden compression at the surface) and then stretching and squeezing those particles to accommodate that stress. A compression (which we may measure or draw as a peak) does not come without a stretching (a dilation or trough) of particles on either side. So a side lobe (or a dilation) has to exist in a way: the particles are connected together and stretch and squeeze when they feel pressure.
Choice of wavelet matters
There was more from Doug McClymont, who’s always up for some chat about wavelets. He pointed out that although high-bandwidth Ormsby wavelets have more sidelobes, they generally have lower amplitudes than a Ricker wavelet, whose sidelobes always have the same ampitude (exactly \( 2 \mathrm{e}^{-3/2} \)). He added:
I tend not to use Ricker wavelets for very much as you can't control the bandwidth of them (just the peak frequency) so they tend to be very narrow-band and have quite high (and constant) amplitude side lobes. As I work a lot with broadband seismic data I use Ormsby wavelets much more for any well-ties and seismic modelling.
Good reasons to use an Ormsby wavelet as your analaytic wavelet of choice! Check out this other post all about Ormsby wavelets and how to make them.
What do you think? Do you have an intuitive explanation for why wavelets have sidelobes? Ideally shorter than mine!































 Except where noted, this content is licensed
Except where noted, this content is licensed {kind=link}