
July linkfest
/It's linkfest time again. All the links, in one handy post.
First up — I've seen some remarkable scientific visualizations recently. For example, giant ocean vortices spiralling across the globe (shame about the rainbow colourbar though). Or the trillion-particle Dark Sky Simulation images we saw at SciPy. Or this wonderful (real, not simulated) video by the Perron Group at MIT:
Staying with visuals, I highly recommend reading anything by Mike Bostock, especially if you're into web technology. The inventor of D3.js, a popular data viz library, here's his exploration of algorithms, from sampling to sorting. It's more conceptual than straight up visualization of data, but no less insightful.
And I recently read about some visual goodness combined with one of my favourite subjects, openness. Peter Falkingham, a palaeontologist at the Royal Vetinary College and Brown University, has made a collection of 3D photographs of modern tracks and traces available to the world. He knows his data is more impactful when others can use it too.
Derald Smith and sedimentology
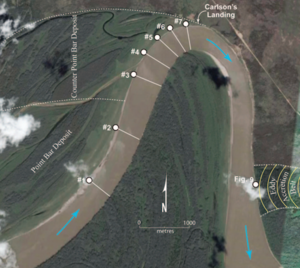 From Smith et al. (2009) in SEPM Special Publication No. 97.The geological world was darkened by the death of Derald Smith on 18 June. I met Derald a few times in connection with working on the McMurray Formation of Alberta, Canada during my time at ConocoPhillips. We spent an afternoon examining core and seismic data, and speculating about counter-point-bars, a specialty of his. He was an intuitive sedimentologist whose contributions will be remembered for many years.
From Smith et al. (2009) in SEPM Special Publication No. 97.The geological world was darkened by the death of Derald Smith on 18 June. I met Derald a few times in connection with working on the McMurray Formation of Alberta, Canada during my time at ConocoPhillips. We spent an afternoon examining core and seismic data, and speculating about counter-point-bars, a specialty of his. He was an intuitive sedimentologist whose contributions will be remembered for many years.
Another geological Smith is being celebrated in September at the Geological Society of London's annual William Smith Meeting. The topic this year is The Future of Sequence Stratigraphy: Evolution or Revolution? Honestly, my first thought was "hasn't that conversation been going on since 1994?", but on closer inspection, it promises to be an interesting two days on 'source-to-sink', 'landscape into rock', and some other recent ideas.
The issue of patents reared up in June when Elon Musk of Tesla Motors announced the relaxation of their patents — essentially a promise not to sue anyone using one of their patented technology. He realizes that a world where lots of companies make electric vehicles is better for Tesla. I wrote a piece about patents in our industry.
Technology roundup
A few things that caught our eye online:
- Along with our good friend Duncan Child, we started Software Underground, a dicussion group on subsurface software and entrepreneurship. It's in private beta for now — follow the links to request an invite.
- We like colour. Matteo Niccoli's tutorial on colourmaps is out tomorrow in the August issue of The Leading Edge.
- Colour came up at SciPy too — check out Kristen Thyng's talk at SciPy.
- NASA scientist Rob Simmon tweeted last month about HCL Wizard, a wonderful new perceptual colour palette tool
- WellDatabase.com is a new commercial site trying to unify access to public well data in the US. We still prefer Ted Kiernan's more open approach with PublicWellData.com, but competition is always good.
- Rob Smallshire of Sixty North in Norway has rescued one of the few open tools that can read and write SEG Y data — here's segpy!
Last thing: did you know that the unit of acoustic impedance is the Rayl? Me neither.
Previous linkfests: April — January — October.
The figure is from Smith et al. (2009), Stratigraphy of counter-point-bar and eddy accretion deposits in low-energy meander belts of the Peace–Athabasca delta, northeast Alberta, Canada. In: SEPM Special Publication No. 97, ISBN 978-1-56576-305-0, p. 143–152. It is copyright of SEPM, and used here in accordance with their terms.















 Except where noted, this content is licensed
Except where noted, this content is licensed