
Not picking parameters
/I like socks. Bright ones. I've liked bright socks since Grade 6. They were the only visible garment not governed by school uniform, or at least not enforced, and I think that was probably the start of it. The tough boys wore white socks, and I wore odd red and green socks. These days, my favourites are Cole & Parker, and the only problem is: how to choose?
 Last Tuesday I wrote about choosing parameters for geophysical algorithms — window lengths, velocities, noise levels, and so on. Like choosing socks, it's subjective, and it's hard to find a pair for every occasion. The comments from Matteo, Toastar, and GuyM raised an interesting question: maybe the best way to pick parameters is to not pick them? I'm not talking about automatically optimizing parameters, because that's still choosing. I'm talking about not choosing at all.
Last Tuesday I wrote about choosing parameters for geophysical algorithms — window lengths, velocities, noise levels, and so on. Like choosing socks, it's subjective, and it's hard to find a pair for every occasion. The comments from Matteo, Toastar, and GuyM raised an interesting question: maybe the best way to pick parameters is to not pick them? I'm not talking about automatically optimizing parameters, because that's still choosing. I'm talking about not choosing at all.
How many ways can we think of to implement this non-choice? I can think of four approaches, but I'm not 100% sure they're all different, or if I can even describe them...
 Is the result really optimal, or just a hard-to-interpret patchwork?
Is the result really optimal, or just a hard-to-interpret patchwork?
Adaptivity
Well, okay, we still choose, but we choose a different value everywhere depending on local conditions. A black pair for a formal function, white for tennis, green for work, and polka dots for special occasions. We can adapt to any property (rather like automatic optimization), along any dimension of our data: spatially, azimuthally, temporally, or frequentially (there's a word you don't see every day).
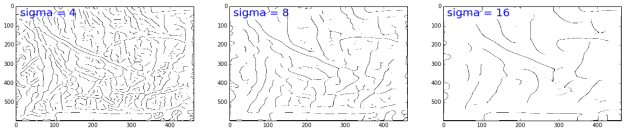
Imagine computing seismic continuity. At each sample, we might evaluate some local function — such as contrast — for a range of window sizes. Or, when smoothing, we might specifiy some minimum signal loss compared to the original. We end up using a different value everywhere, and expect an optimal result.
One problem is that we still have to choose a cost function. And to be at all useful, we would need to produce two new data products, besides the actual result: a map of the parameter's value, and a map of the residual cost, so to speak. In other words, we need a way to know what was chosen, and how satisfactory the choice was.
Stochastic shotgun
We could fall back on that geostatistical favourite and pick the parameter values stochastically, grabbing socks at random out of the drawer. This works, but I need a lot of socks to have a chance of getting even a local maximum. And we run into the old problem of really not knowing what to do with all the realizations. Common approaches are to take the P50, P10, and P90, or to average them. Both of these approaches make me want to ask: Why did I generate all those realizations?
Experimental design methods
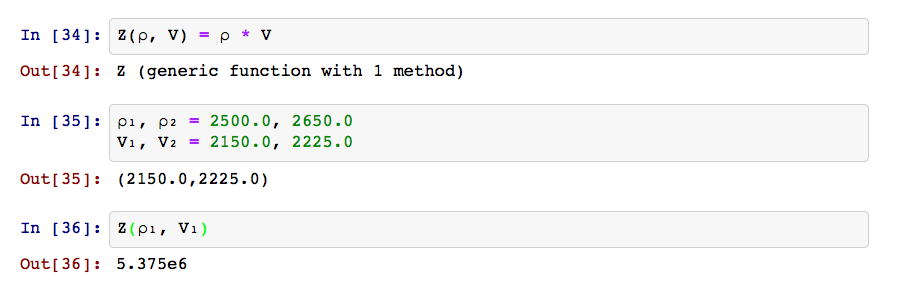
 The design of experiments is a big deal in the life sciences, but for some reason rarely (never?) talked about in geoscience. Applying a cost function, or even just visual judgment, to a single parameter is perhaps trivial, but what if you have two variables? Three? What if they are non-linear and covariant? Then the optimization process amounts to a sticky inverse problem.
The design of experiments is a big deal in the life sciences, but for some reason rarely (never?) talked about in geoscience. Applying a cost function, or even just visual judgment, to a single parameter is perhaps trivial, but what if you have two variables? Three? What if they are non-linear and covariant? Then the optimization process amounts to a sticky inverse problem.
Fortunately, lots of clever people have thought about these problems. I've even seen them implemented in subsurface software. Cool-sounding combinatorial reduction techniques like Greco-Latin squares, or Latin hypercubes offer ways to intelligently sample the parameter space and organize the results. We could do the same with socks, evaluating pattern and toe colour separately...
The mixing board
 There is another option: the mixing board. Like a music producer, a film editor, or the Lytro camera, I can leave the raw data in place, and always work from the masters. Given the right tools, I can make myself just the right pair of socks whenever I like.
There is another option: the mixing board. Like a music producer, a film editor, or the Lytro camera, I can leave the raw data in place, and always work from the masters. Given the right tools, I can make myself just the right pair of socks whenever I like.
This way we can navigate the parameter space, applying views, processes, or other tools on the fly. Clearly this would mean changing everything about the way we work. We'd need a totally different approach not just to interpretation, but to the entire subsurface characterization workflow.
Are there other ways to avoid choosing? What are people using in other industries, or other sciences? I think we need to invite some experimental design and machine learning people to SEG...
![]() The quilt image is by missvancamp on Flickr and licensed CC-BY. The spools are by surfzone on Flickr, licensed CC-BY. Many thanks to Cole & Parker for permission to use the sock images, despite not knowing what on earth I was going to do with them. Buy their socks! They're Canadian and everything.
The quilt image is by missvancamp on Flickr and licensed CC-BY. The spools are by surfzone on Flickr, licensed CC-BY. Many thanks to Cole & Parker for permission to use the sock images, despite not knowing what on earth I was going to do with them. Buy their socks! They're Canadian and everything.













 Except where noted, this content is licensed
Except where noted, this content is licensed