
This year's social coding events
/If you've always wondered what goes on at our hackathons, make 2018 the year you find out. There'll be plenty of opportunities. We'll be popping up in Salt Lake City, right before the AAPG annual meeting, then again in Copenhagen, before EAGE. We're also running events at the AAPG and EAGE meetings. Later, in the autumn, we'll be making some things happen around SEG too.
If you just want to go sign up right now, head to the Events page. If you want more deets first, read on.
Salt Lake City in May: machine learning and stratigraphy
This will be one of our 'traditional' hackathons. We're looking for 7 or 8 teams of four to come and dream up, then hack on, new ideas in geostatistics and machine learning, especially around the theme of stratigraphy. Not a coder? No worries! Come along to the bootcamp on Friday 18 May and acquire some new skills. Or just show up and be a brainstormer, tester, designer, or presenter.

Thank you to Earth Analytics for sponsoring this event. If you'd like to sponsor it too, check out your options. The bottom line is that these events cost about $20,000 to put on, so we appreciate all the help we can get.
It doesn't stop with the hackathon demos on Sunday. At the AAPG ACE, Matt is part of the team bringing you the Machine Learning Unsession on Wednesday afternoon. If you're interested in the future of computation and geoscience, come along and be heard. It wouldn't be the same without you.
Copenhagen in June: visualization and interaction
After events in Vienna in 2016 and Paris in 2017, we're looking forward to being back in Europe in June. The weekend before the EAGE conference, we'll be hosting the Subsurface Hackathon once again. Partnering with Dell EMC and Total E&P, as last year, we'll be gathering 60 eager geoscientists to explore data visualization, from plotting to virtual reality. I can't wait.
In the EAGE Exhibition itself, we're cooking up something else entirely. The Codeshow is a new kind of conference event, mixing coding tutorials with demos from the hackathon and even some mini-hackathon projects to get you started on your own. It's 100% experimental, just the way we like it.
Anaheim in October: something exciting
We'll be at SEG in Anaheim this year, in the middle of October. No idea what exactly we'll be up to, but there'll be a hackathon for sure (sign up for alerts here). And tacos, lots of those.
You can get tickets to most of these events on the Event page. If you have ideas for future events, or questions about them, drop us a line or leave a comment on this post!
I'll leave you with a short and belated look at the hackathon in Paris last year...
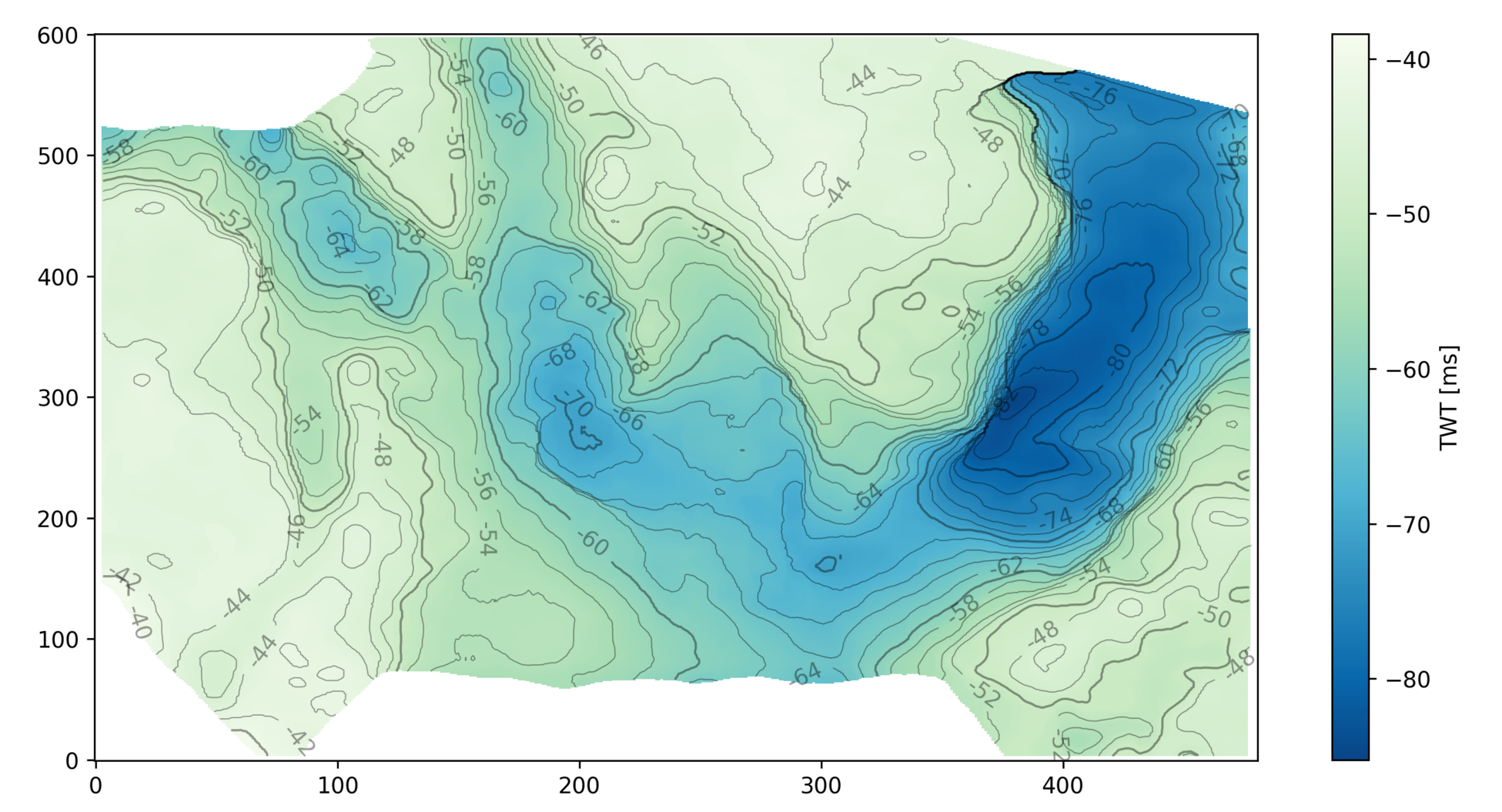
A quick look at the Subsurface Hackathon in Paris, June 2017.


































 Except where noted, this content is licensed
Except where noted, this content is licensed