
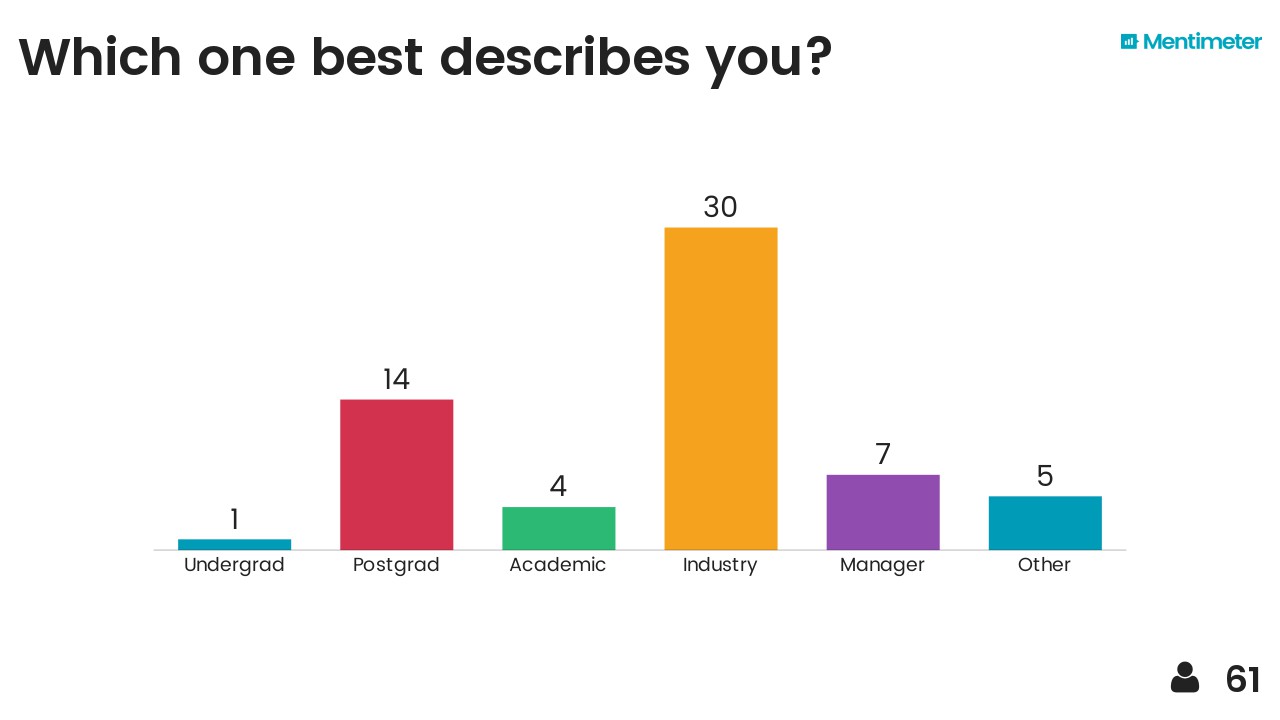
The norm and simple solutions
/Last time I wrote about different ways of calculating distance in a vector space — say, a two-dimensional Euclidean plane like the streets of Portland, Oregon. I showed three ways to reckon the distance, or norm, between two points (i.e. vectors). As a reminder, using the distance between points u and v on the map below this time:
$$ \|\mathbf{u} - \mathbf{v}\|_1 = |u_x - v_x| + |u_y - v_y| $$
$$ \|\mathbf{u} - \mathbf{v}\|_2 = \sqrt{(u_x - v_x)^2 + (u_y - v_y)^2} $$
$$ \|\mathbf{u} - \mathbf{v}\|_\infty = \mathrm{max}(|u_x - v_x|, |u_y - v_y|) $$
Let's think about all the other points on Portland's streets that are the same distance away from u as v is. Again, we have to think about what we mean by distance. If we're walking, or taking a cab, we'll need to think about \(\ell_1\) — the sum of the distances in x and y. This is shown on the left-most map, below.
For simplicity, imagine u is the origin, or (0, 0) in Cartesian coordinates. Then v is (0, 4). The sum of the distances is 4. Looking for points with the same sum, we find the pink points on the map.
If we're thinking about how the crow flies, or \(\ell_2\) norm, then the middle map sums up the situation: the pink points are all equidistant from u. All good: this is what we usually think of as 'distance'.

The \(\ell_\infty\) norm, on the other hand, only cares about the maximum distance in any direction, or the maximum element in the vector. So all points whose maximum coordinate is 4 meet the criterion: (1, 4), (2, 4), (4, 3) and (4, 0) all work.
You might remember there was also a weird definition for the \(\ell_0\) norm, which basically just counts the non-zero elements of the vector. So, again treating u as the origin for simplicity, we're looking for all the points that, like v, have only one non-zero Cartesian coordinate. These points form an upright cross, like a + sign (right).
So there you have it: four ways to draw a circle.
Wait, what?
A circle is just a set of points that are equidistant from the centre. So, depending on how you define distance, the shapes above are all 'circles'. In particular, if we normalize the (u, v) distance as 1, we have the following unit circles:
It turns out we can define any number of norms (if you like the sound of \(\ell_{2.4}\) or \(\ell_{240}\) or \(\ell_{0.024}\)...) but most of the time, these will suffice. You can probably imagine the shapes of the unit circles defined by these other norms.
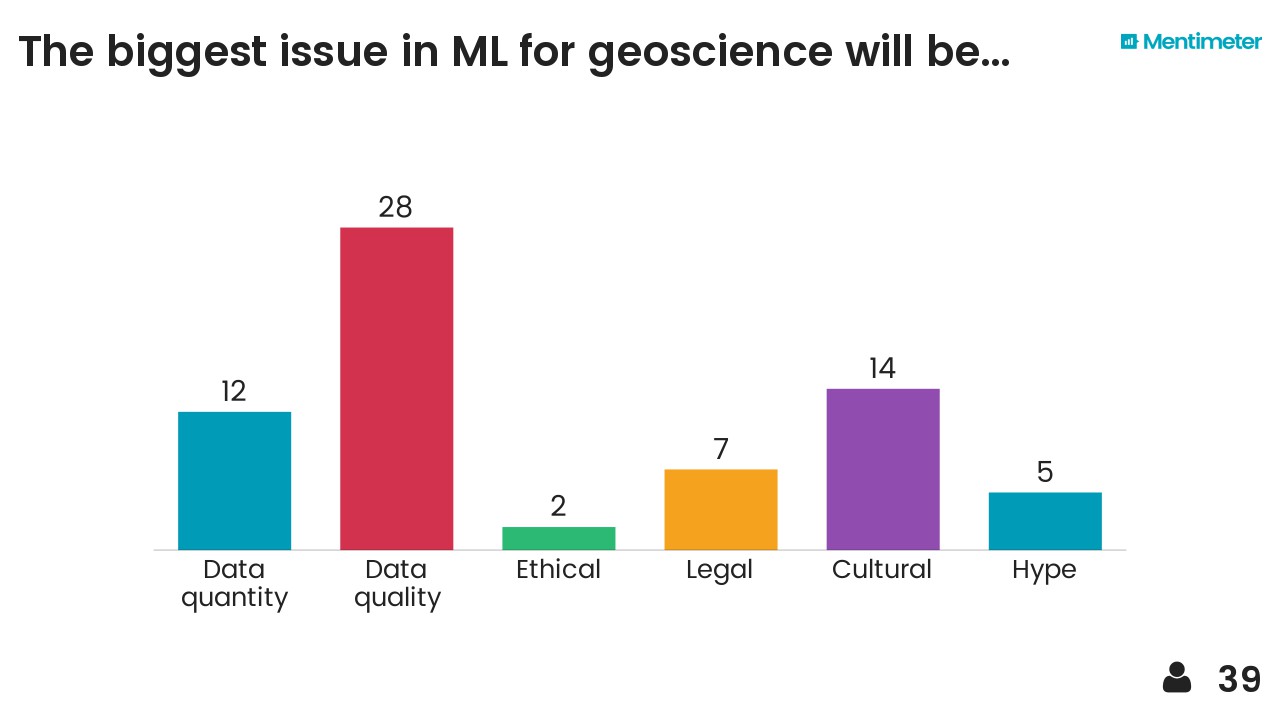
What can we do with this stuff?
Let's think about solving equations. Think about solving this:
$$ x + 2y = 8 $$

I'm sure you can come up with a soluiton in your head, x = 6 and y = 1 maybe. But one equation and two unknowns means that this problem is underdetermined, and consequently has an infinite number of solutions. The solutions can be visualized geometrically as a line in the Euclidean plane (right).
But let's say I don't want solutions like (3.141590, 2.429205) or (2742, –1367). Let's say I want the simplest solution. What's the simplest solution?

This is a reasonable question, but how we answer it depends how we define 'simple'. One way is to ask for the nearest solution to the origin. Also reasonable... but remember that we have a few different ways to define 'nearest'. Let's start with the everyday definition: the shortest crow-flies distance from the origin. The crow-flies, \(\ell_2\) distances all lie on a circle, so you can imagine starting with a tiny circle at the origin, and 'inflating' it until it touches the line \(x + 2y - 8 = 0\). This is usually called the minimum norm solution, minimized on \(\ell_2\). We can find it in Python like so:
import numpy.linalg as la A = [[1, 2]] b = [8] la.lstsq(A, b)
The result is the vector (1.6, 3.2). You could almost have worked that out in your head, but imagine having 1000 equations to solve and you start to appreciate numpy.linalg. Admittedly, it's even easier in Octave (or MATLAB if you must) and Julia:
A = [1 2] b = [8] A \ b

But remember we have lots of norms. It turns out that minimizing other norms can be really useful. For example, minimizing the \(\ell_1\) norm — growing a diamond out from the origin — results in (0, 4). The \(\ell_0\) norm gives the same sparse* result. Minimizing the \(\ell_\infty\) norm leads to \( x = y = 8/3 \approx 2.67\).
This was the diagram I wanted to get to when I started with the 'how far away is the supermarket' business. So I think I'll stop now... have fun with Norm!
* I won't get into sparsity now, but it's a big deal. People doing big computations are always looking for sparse representations of things. They use less memory, are less expensive to compute with, and are conceptually 'neater'. Sparsity is really important in compressed sensing, which has been a bit of a buzzword in geophysics lately.
















































































 Except where noted, this content is licensed
Except where noted, this content is licensed