
Making images or making prospects?
/Well-rounded geophysicists will have experience in each of the following three areas: acquisition, processing, and interpretation. Generally speaking, these three areas make up the seismic method, each requiring highly specified knowledge and tools. Historically, energy companies used to control the entire spectrum, owning the technology, the know-how and the risk, but that is no longer the case. Now, service companies do the acquisition and the processing. Interpretation is largely hosted within E & P companies, the ones who buy land and drill wells. Not only has it become unreasonable for a single geophysicist to be proficient across the board, but organizational structures constrain any particular technical viewpoint.
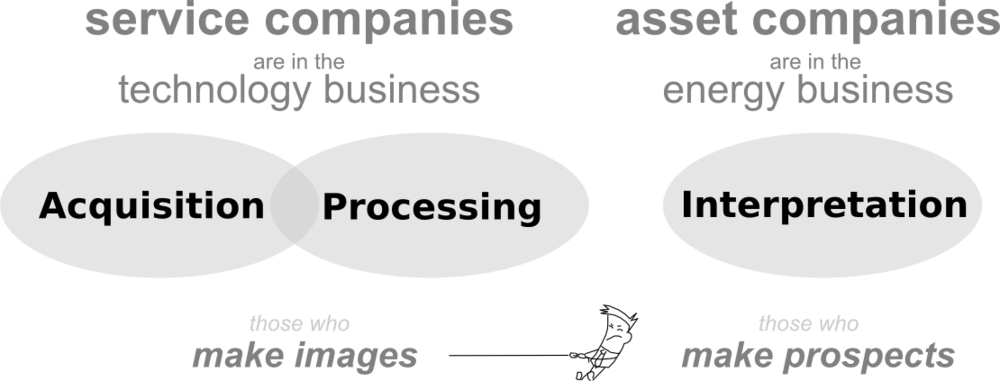 Aligning with the industry's strategy, if you are a geophysicist, you likely fall into one of two camps: those who make images, or those who make prospects. One set of people to make the data, one set of people to do the interpretation.
Aligning with the industry's strategy, if you are a geophysicist, you likely fall into one of two camps: those who make images, or those who make prospects. One set of people to make the data, one set of people to do the interpretation.
This seems very un-scientific to me.
Where does science fit in?
Science, the standard approach of rational inquiry and accruing knowledge, is largely vacant from the applied geophysical business landscape. But, when science is used as a model, making images and making prospects are inseperable.
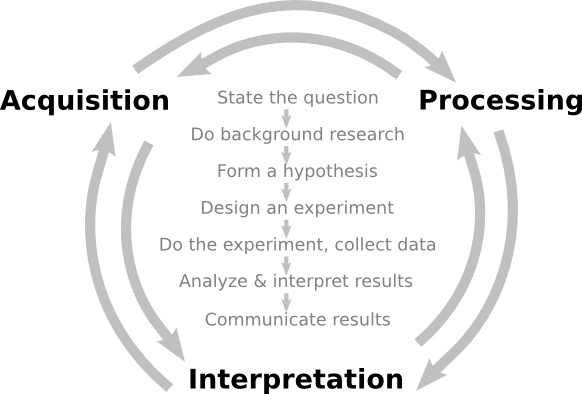 Can applied geophysics use scientific behaviour as a central anchor across disciplines?
Can applied geophysics use scientific behaviour as a central anchor across disciplines?
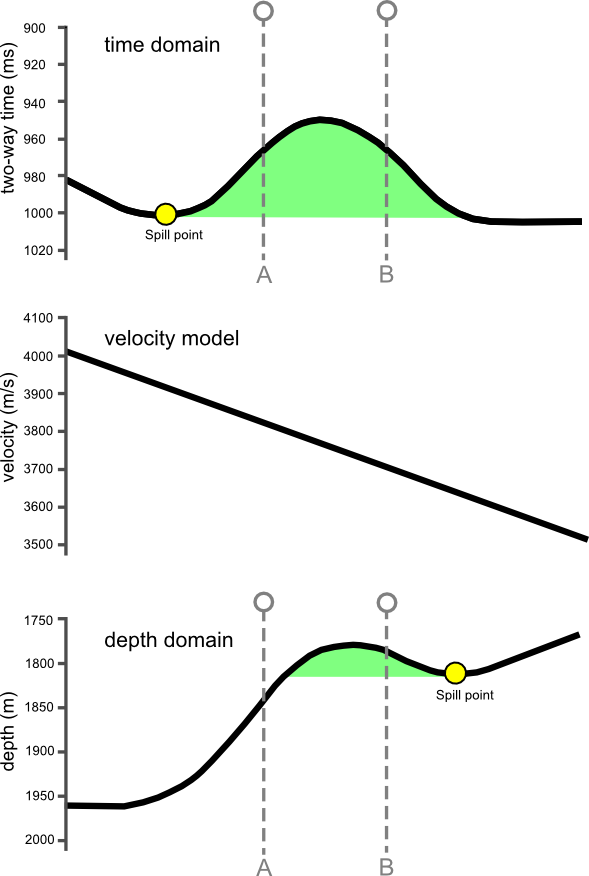
There is a significant amount of science that is needed in the way that we produce observations, in the way that we make images. But the business landscape built on linear procedures leaves no wiggle room for additional testing and refinement. How do processors get better if they don't hear about their results? As a way of compensating, processing has deflected away from being a science of questioning, testing, and analysis, and moved more towards, well,... a process.
The sure-fire way to build knowledge and decrease uncertainty, is through experimentation and testing. In this sense this notion of selling 'solutions', is incompatible with scientific behavior. Science doesn't claim to give solutions, science doesn't claim to give answers, but it does promise to address uncertainty; to tell you what you know.
In studying the earth, we have to accept a lack of clarity in our data, but we must not accept mistakes, errors, or mediocrity due to shortcomings in our shared methodologies.
We need a new balance. We need more connectors across these organizational and disciplinary divides. That's where value will be made as industry encounters increasingly tougher problems. Will you be a connector? Will you be a subscriber to science?
Hall, M (2012). Do you know what you think you know? CSEG Recorder 37 (2), February 2012, p 26–30. Free to download from CSEG.










 Except where noted, this content is licensed
Except where noted, this content is licensed