
Open up
/After a short trip to Houston, today I am heading to London, Ontario, for a visit with Professor Burns Cheadle at the University of Western Ontario. I’m stoked about the trip. On Saturday I’m running my still-developing course on writing for geoscientists, and tomorrow I’m giving the latest iteration of my talk on openness in geoscience. I’ll post a version of it here once I get some notes into the slides. What follows is based on the abstract I gave Burns.
A recent survey by APEGBC's Innovation magazine revealed that geoscience is not among the most highly respected professions. Only 20% of people surveyed had a ‘great deal of respect’ for geologists and geophysicists, compared to 30% for engineers, and 40% for teachers. This is far from a crisis, but as our profession struggles to meet energy demands, predict natural disasters, and understand environmental change, we must ask, How can we earn more trust? Perhaps more openness can help. I’m pretty sure it can’t hurt.
Many people first hear about ‘open’ in connection with software, but open software is just one point on the open compass. And even though open software is free, and can spread very easily in principle, awareness is a problem—open source marketing budgets are usually small. Open source widgets are great, but far more powerful are platforms and frameworks, because these allow geoscientists to focus on science, not software, and collaborate. Emerging open frameworks include OpendTect and GeoCraft for seismic interpretation, and SeaSeis and BotoSeis for seismic processing.
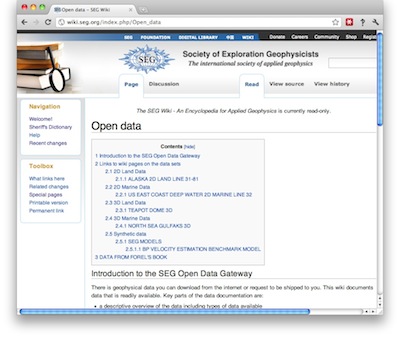 If open software is important for real science, then open data are equally vital because they promote reproducibility. Compared to the life sciences, where datasets like the Human Genome Project and Visible Human abound, the geosciences lag. In some cases, the pieces exist already in components like government well data, the Open Seismic Repository, and SEG’s list of open datasets, but they are not integrated or easy to find. In other cases, the data exist but are obscure and lack a simple portal. Some important plays, of global political and social as well as scientific interest, have little or no representation: industry should release integrated datasets from the Athabasca oil sands and a major shale gas play as soon as possible.
If open software is important for real science, then open data are equally vital because they promote reproducibility. Compared to the life sciences, where datasets like the Human Genome Project and Visible Human abound, the geosciences lag. In some cases, the pieces exist already in components like government well data, the Open Seismic Repository, and SEG’s list of open datasets, but they are not integrated or easy to find. In other cases, the data exist but are obscure and lack a simple portal. Some important plays, of global political and social as well as scientific interest, have little or no representation: industry should release integrated datasets from the Athabasca oil sands and a major shale gas play as soon as possible.
Open workflows are another point, because they allow us to accelerate learning, iteration, and failure, and thus advance more quickly. We can share easily but slowly and inefficiently by publishing, or attending meetings, but we can also write blogs, contribute to wikis, tweet, and exploit the power of the internet as a dynamic, multi-dimensional network, not just another publishing and consumption medium. Online readers respond, get engaged, and become creators, completing the feedback loop. The irony is that, in most organizations, it’s easier to share with the general public, and thus competitors, than it is to share with colleagues.
The fourth point of the compass is in our attitude. An open mindset recognizes our true competitive strengths, which typically are not our software, our data, or our workflows. Inevitably there are things we cannot share, but there’s far more that we can. Industry has already started with low-risk topics for which sharing may be to our common advantage—for example safety, or the environment. The question is, can we broaden the scope, especially to the subsurface, and make openness the default, always asking, is there any reason why I shouldn’t share this?
In learning to embrace openness, it’s important to avoid some common misconceptions. For example, open does not necessarily mean free-as-in-beer. It does not require relinquishing ownership or rights, and it is certainly not the same as public domain. We must also educate ourselves so that we understand the consequences of subtle and innocuous-seeming clauses in licences, for example those pertaining to non-commerciality. If we can be as adept in this new language as many of us are today in intellectual property law, say, then I believe we can accelerate innovation in energy and build trust among our public stakeholders.
So what are you waiting for? Open up!
















 Except where noted, this content is licensed
Except where noted, this content is licensed