
100 years of seismic reflection
/Where would we be without seismic reflection? Is there a remote sensing technology that is as unlikely, as difficult, or as magical as the seismic reflection method? OK, maybe neutrino tomography. But anyway, seismic has contributed a great deal to society — helping us discover and describe hydrocarbon resources, aquifers, geothermal anomalies, sea-floor hazards, and plenty more besides.
It even indirectly led to the integrated circuit, but that’s another story.
Depending on who you ask, 9 August 2021 may or may not be the 100th anniversary of the seismic reflection method. Or maybe 5th August. Or maybe it was June or July. But there’s no doubt that, although the first discovery with seismic did not happen until several years later, 1921 was the year that the seismic reflection method was invented.

Ryan, Karcher and Haseman in the field, August 1921. Badly colourized by an AI.
The timeline
I’ve tried to put together a timeline by scouring a few sources. Several people — Clarence Karcher (a physicist), William Haseman (a physicist), Irving Perrine (a geologist), William Kite (a geologist) at the University of Oklahoma, and later Daniel Ohern (a geologist) — conducted the following experiments:
12 April 1919 — Karcher recorded the first exploration seismograph record near the National Bureau of Standards (now NIST) in Washington, DC.
1919 to 1920 — Karcher continues his experimentation.
April 1921 — Karcher, whilst working at the National Bureau of Standards in Washington, DC, designed and constructed apparatus for recording seismic reflections.
4 June 1921 — the first field tests of the refleciton seismograph at Belle Isle, Oklahoma City, using a dynamite source.
6 June until early July — various profiles were acquired at different offsets and spacings.
14 July 1921 — Testing in the Arbuckle Mountains. The team of Karcher, Haseman, Ohern and Perrine determined the velocities of the Hunton limestone, Sylvan shale, and Viola limestone.
Early August 1921 — The group moves to Vines Branch where “the world’s first reflection seismograph geologic section was measured”, according to a commemorative plaque on I-35 in Oklahoma. That plaque claims it was 9 August, but there are also records from 5 August. The depth to the Viola limestone is recorded and observed to change with geological structure.
1 September 1921 — Karcher, Haseman, and Rex Ryan (a geologist) conduct experiments at the Newkirk Anticline near Ponca City.
13 September 1921 — a survey was begun for Marland Oil Company and continues into October. Success seems mixed.
So what did these physicists and geologists actually do? Here’s an explanation from Bill Dragoset in his excellent review of the history of seismic from 2005:
“Using a dynamite charge as a seismic source and a special instrument called a seismograph, the team recorded seismic waves that had traveled through the subsurface of the earth. Analysis of the recorded data showed that seismic reflections from a boundary between two underground rock layers had been detected. Further analysis of the data produced an image of the subsurface—called a seismic reflection profile—that agreed with a known geologic feature. That result is widely regarded as the first proof that an accurate image of the earth’s subsurface could be made using reflected seismic waves. ”
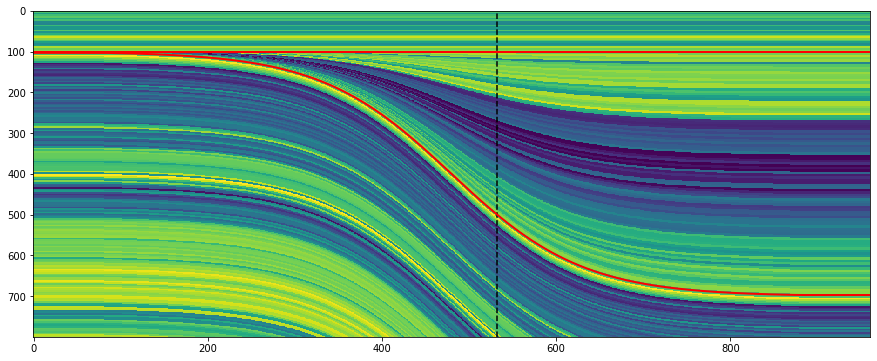
The data was a bit hard to interpret! This is from William Schriever’s paper:

Nonetheless, here’s the section the team managed to draw at Vine Creek. This is the world’s first reflection seismograph section — 9 August 1921:

The method took a few years to catch on — and at least a few years to be credited with a discovery. Karcher founded Geophysical Research Corporation (now Sercel) in 1925, then left and founded Geophysical Service International — which later spun out Texas Instruments — in 1930. And, eventually, seismic reflection turned into an idsutry worth tens of billions of dollars per year. Sometimes.
References
Bill Dragoset, (2005), A historical reflection on reflections, The Leading Edge 24: s46-s70. https://doi.org/10.1190/1.2112392
Clarence Karcher (1932). DETERMINATION OF .SUBSURFACE FORMATIONS. Patent no. 1843725A. Patented 2 Feb 1932.
William Schriever (1952). Reflection seismograph prospecting; how it started; contributions. Geophysics 17 (4): 936–942. doi: https://doi.org/10.1190/1.1437831
B Wells and K Wells (2013). American Oil & Gas Historical Society. American Oil & Gas Historical Society. Exploring Seismic Waves. Last Updated: August 7, 2021. Original Published Date: April 29, 2013.

















 Except where noted, this content is licensed
Except where noted, this content is licensed