
The order of stratigraphic sequences
/Much of stratigraphic interpretation depends on a simple idea:
Depositional environments that are adjacent in a geographic sense (like the shoreface and the beach, or a tidal channel and tidal mudflats) are adjacent in a stratigraphic sense, unless separated by an unconformity.
Usually, geologists are faced with only the stratigraphic picture, and are challenged with reconstructing the geographic picture.
One interpretation strategy might be to look at which rocks tend to occur together in the stratigraphy. The idea is that rock types tend to be associated with geographic environments — maybe fine sand on the shoreface, coarse sand on the beach; massive silt in the tidal channel, rhythmically laminated mud in the mud-flats. Since if two rocks tend to occur together, their environments were probably adjacent, we can start to understand associations between the rock types, and thus piece together the geographic picture.
So which rock types tend to occur together, and which juxtapositions are spurious — perhaps the result of allocyclic mechanisms like changes in relative sea-level, or sediment supply? To get at this question, some stratigraphers turn to Markov chain analysis.
What is a Markov chain?
Markov chains are sequences of events, or states, resulting from a Markov process. Here’s how Wikipedia describes a Markov process:
“A stochastic process that satisfies the Markov property (sometimes characterized as “memorylessness”). Roughly speaking, a process satisfies the Markov property if one can make predictions for the future of the process based solely on its present state just as well as one could knowing the process’s full history, hence independently from such history; i.e., conditional on the present state of the system, its future and past states are independent.”
So if we believe that a stratigraphic sequence (I’m using ‘sequence’ here in the most general sense) can be modeled by a process like this — i.e. that its next state depends substantially on its present state — then perhaps we can model it as a Markov chain.
For example, we might have a hunch that we can model a shallow marine system as a sequence like:
offshore mudstone > lower shoreface siltstone > upper shoreface sandstone > foreshore sandstone
Then we might expect to see these transitions occur more often than other, non-successive transitions. In other words — if we compare the transition frequencies we observe to the transition frquencies we would expect from a random sequence of the same beds in the same proportions, then autocyclic or genetic transitions might happen unusually frequently.
The Powers & Easterling method
Several workers have gone down this path. The standard approach seems to be that of Powers & Easterling (1982). Here are the steps they describe:
Count the upwards transitions for each rock type. This results in a matrix of counts. Here’s the transition frequency matrix for the example used in the Powers & Easterling paper, in turn taken from Gingerich (1969):
data = [[ 0, 37, 3, 2], [21, 0, 41, 14], [20, 25, 0, 0], [ 1, 14, 1, 0]]
Compute the expected counts by an iterative process, which usually converges in a few steps. The expected counts represent what Goodman (1968) called a ‘quasi-independence’ model — a random sequence:
array([[ 0. , 31.3, 8.2, 2.6], [31.3, 0. , 34.1, 10.7], [ 8.2, 34. , 0. , 2.8], [ 2.6, 10.7, 2.8, 0. ]])
Now we can compare our observed frequencies with the expected ones in two ways. First, we can inspect the \(\chi^2\) statistic, and compare it with the \(\chi^2\) distribution, given the degrees of freedom (5 in this case). In this example, it’s 35.7, which is beyond the 99.999th percentile of the chi-squared distribution. This rejects the hypothesis of quasi-independence. In other words: the succession appears to be organized. Phew!
Secondly, we can compute a matrix of so-called normalized differences. This lets us compare the observed and expected data. By calculating Z-scores, which are approximately normally distributed; since 95% of the distribution falls between −2 and +2, any value greater in magnitude than 2 is ‘fairly unusual’, in the words of Powers & Easterling. In the example, we can see that the large number of transitions from C (third row) to A (first column) is anomalous:
array([[ 0. , 1. , -1.8, -0.3], [-1.8, 0. , 1.2, 1. ], [ 4.1, -1.6, 0. , -1.7], [-1. , 1. , -1.1, 0. ]])

The normalized difference matrix can also be interpreted as a directed graph, indicating the ‘strengths’ of the connections (edges) between rock types (nodes):
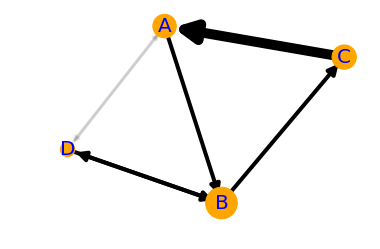
It would be all too easy to over-interpret this graph — B and D seem to go together, as do A and C, and C tends to pass into A, which tends to pass into a B/D system before passing back into C — and one could get carried away. But as a complement to sedimentological interpretation, knowledge of processes and the succession in hand, perhaps inspecting Markov chains can help understand the stratigraphic story.
One last thing… there is another use for Markov chains. We can also use the model to produce stochastic realizations of stratigraphy. These will share the same statistics as the original data, but are otherwise quite random. Here are 20 random beds generated from our model:
'ABABCBABABCABDABABCA'The code to build your own Markov chains is all in this notebook. It’s very much a work in progress. Eventually I hope to merge it into the striplog library, but for now it’s a ‘minimum viable product’. Stay tuned for more on striplog.
![]() ⇐ Launch the notebook right here in your browser!
⇐ Launch the notebook right here in your browser!
References
Gingerich, PD (1969). Markov analysis of cyclic alluvial sediments. Journal of Sedimentary Petrology, 39, p. 330-332. https://doi.org/10.1306/74D71C4E-2B21-11D7-8648000102C1865D
Goodman, LA (1968), The analysis of cross-classified data: independence, quasi-independence, and interactions in contingency tables with or without missing entries. Journal of American Statistical Association 63, p. 1091-1131. https://doi.org/10.2307/2285873
Powers, DW and RG Easterling (1982). Improved methodology for using embedded Markov chains to describe cyclical sediments. Journal of Sedimentary Petrology 52 (3), p. 0913-0923. https://doi.org/10.1306/212F808F-2B24-11D7-8648000102C1865D





 Except where noted, this content is licensed
Except where noted, this content is licensed